نمونه گیری و برآورد حجم نمونه:
بخش نهایی طرح پژوهش به مسائل شرکت کنندگان با آزمودنیها مربوط می شود.
در واقع در اینجا پژوهشگر باید به پرسش چه کسی را مطالعه خواهید کرد و نصد دارید نتایج پژوهش را بر روی چه کسانی اعمال نمایید؟، پاسخ گوید.
در این مقاله به مسائل مهمی چون نمونه برداری و روشهای اساسی آن، حجم نمونه، که در روایی طرح پژوهش اثر مهمی ایفا می کند، چگونگی برآورد حجم نمونه در مطالعات و طرحهای مختلف خواهیم پرداخت.
نمونه برداری
مفهوم نمونه برداری به فرایند تعیین و انتخاب شرکت کنندگان در مطالعه اشاره دارد.
مراحل نمونه برداری به ترتیب زمانی عبارت اند از:
١. تعيين جامعه آماج
٢. انتخاب روش نمونه برداری؛
٣. تعیین حجم نمونه.
هر یک از این مراحل را به ترتیب تشریح و سپس به روی آوردهای مختلف در نمونه برداری اشاره خواهیم نمود.
هر چند زبان به کار رفته در اینجا بیشتر به سنتهای پژوهشی کمی نزدیک است، کاربردهای فراگیر روشهای نمونه برداری را نیز، که قابل تعمیم به روشهای کیفی پژوهش است، مورد بحث قرار خواهیم داد.
اگر چه به نظر می رسد که پژوهشهای کیفی کمتر به موضوع «معرف» بودن نمونه مورد مطالعه حساس اند و بیشتر به دنبال یافتن پدیده و افرادی که پدیده مورد نظر را نشان می دهند» هستند، عقیده کلی بر این است که تمامی پژوهشگران اعم از کیفی یا کمی، به طور مستقیم یا غیر مستقیم (آشکار یا ضمنی) بایستی برای موضوع حجم نمونه و چگونگی نمونه برداری پاسخی درخور فراهم سازند.
برای فهم بهتر فرایند نمونه برداری، آن را به شکل ۳ دایره متداخل تصور می کنیم .
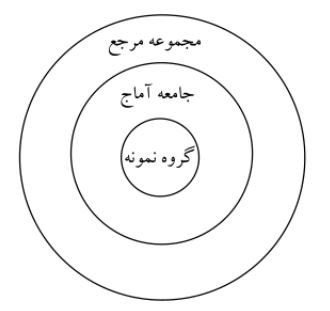
1. جامعه کلی یا مجموعه مرجع جامعه بزرگی است که قرار است نتایج و یافته های مطالعه به آن تعمیم داده شود؛
۲. جامعه آماج گروه مشخصی است که شرکت کنندگان با آزمودنیهای مطالعه از آن انتخاب می شوند؛
٣. گروه نمونه زیر گروه جامعه آماج است و شامل افرادی می شود که در مطالعه شرکت داده می شوند.
گاهی ممکن است بین نمونه ایده ال و نمونه موجود (یا واقعی) فاصله ای وجود داشته باشد. به همین منظور بهتر است از واژه «نمونه مورد نظر در برابر نمونه اکتسابی، استفاده شود تا این مشکل رفع شود؛ برای مثال، ممکن است پژوهشگری به موضوع افسردگی در آن دسته از زنان ایرانی که به پزشک عمومی یا پزشک خانوادگی مراجعه می کنند، علاقه مند باشد.
در اینجا جامعه کلی با مجموعه مرجع ممکن است تمامی زنان ایرانی باشد که به پزشک عمومی مراجعه می کنند و جامعه آماج ممکن است تمامی زنانی باشد که در شهر گرگان در بهمن ماه به پزشک عمومی مراجعه می کنند و نمونه مورد نظر یک زن از هر ۲۰ زنی باشد که در شهر گرگان به پزشک عمومی مراجعه می کنند، اما در عمل ممکن است نمونه به دست آمده زیر مجموعه ای از زنانی باشد که در نهایت مورد مصاحبه و آزمون قرار گرفته اند.
سرشماری جمعیت مجموعه مرجع، جامعه آماج و گروه نمونه مورد نظر یکسان است، هر چند ممکن است نمونه به دست آمده شده کوچک تر از نمونه مورد نظر باشد؛ چرا که همواره گروهی از افراد به دلایلی ثبت نمی شوند با دور از دسترس قرار می گیرند.
به مقادیر کمی که بیانگر ویژگیهای گروه نمونه است، مشخصه آماری" و به مقادیری که بیانگر ویژگیهای جامعه است، مشخصه جامعه یا پارامتر گویند.
معمولا از مشخصه آماری نمونه برای برآورد مشخصه جامعه یا پارامتر جامعه استفاده می شود.
شناخت و دستیابی به پارامترهای جامعه یکی از اهداف اصلی پژوهشی است که تلاش پژوهشگر نیز استنباط و برآورد این پارامترها بر اساس مشخصه های آماری گروه نمونه است؛ برای مثال، شیوع افسردگی در یک گروه نمونه از زنانی که به پزشک عمومی مراجعه می کنند، یک امشخصه آماری، است.
پژوهشگر ممکن است از این مشخصه آماری برای برآورد شیوع افسردگی در جامعه آماج (زنان گرگانی که به پزشک عمومی مراجعه می کنند استفاده کند. در اینجا جامعه زنان گرگانی که به پزشک عمومی مراجعه می کنند و پارامتره محسوب می شود.
قابلیت تعمیم معمولا پژوهشگران تنها به گروهی که روی آن مطالعه انجام می دهند بسنده نمی کنند و در پی آن اند تا بافته هایشان را به گروههای دیگر نیز تعمیم دهند.
به آنچه چنین استنباطی را امکان پذیر می سازد «روایی بیرونی گویند (کوک و کمبل، ۱۹۷۹). روایی بیرونی هر پژوهش را میزان قابلیت آن در پاسخگویی به این سؤال تعیین می کند که تا چه اندازه نتایج و یافته های این مطالعه فراسوی افراد، موقعیتها و با رویدادهایی که در گروه نمونه وجود داشته است به شرایط مشابه آن نیز صدق می کند.
البته باید توجه داشت که موضوع قابلیت تعمیم فقط مربوط به نمونه برداری نیست، بلکه ملاحظات ویژه مربوط به شرایط و موقعیت آزمون، زمان آزمون و مقیاسهای به کار رفته در مطالعه را نیز در بر می گیرد.
به جنبه های اخیر مربوط به روایی بیرونی در فصل ده به هنگام طرح موضوع، تحلیل داده ها و تفسیر یافته ها خواهیم پرداخت.
از دیدگاه نمونه برداری، دو نوع تعمیم وجود دارد:
نوع اول تعمیم از گروه نمونه به جامعه آماج است.
در پژوهشهای کمی به این نوع تعميم استنباط آماری گویند که روشهای مناسبی برای انجام آن وجود دارد. اما این روشها فرضهای خاصی را از قبیل نمونه برداری بدون سوگیری از جامعه آماج مطرح می کنند که به آنها خواهیم پرداخت.
تعميم نوع دوم، تعمیم از جامعه آماج به جامعه دیگر با به مجموعه مرجع بزرگ تر است که این نوع تعمیم بیشتر در بستر معقولیت کلی، انجام پذیر است تا هر نوع بحث آماری؛ مثلا آیا نتایج و یافته های به دست آمده از بیماران بیمارستان الف را که مشکل کمر درد دارند می توان به بیماران بیمارستان ب نیز تعمیم داد؟ یا به مردمی که کمر درد دارند ولی تا به حال به بیمارستان مراجعه نکرده اند؟ با به کل افرادی که در کشور با این مشکل مواجه هستند یا حتی به فرهنگ دیگر چطور؟ چنانچه این گروهها به طور معقولی به یکدیگر شبیه باشند، آنگاه بافته ها را می توان به همه آنها تعمیم داد و اگر شبیه هم نباشند، می بایستی بافته های موجود را فقط در خصوص گروه اصلی، که مطالعه بر روی آنها انجام گرفته، صادق دانست؛ مگر اینکه مطالعه بر روی جمعیت یا گروههای دیگر نیز تکرار شود.
در خصوص مطالعات کیفی و مطالعات موردی بحث تعميم پذیری همواره به معقولیت و قابل باور بودن، یافته ها بستگی دارد که مشابه نوع دوم تعمیم پذیری در روشهای کمی است.
میزان اهمیت روایی بیرونی به نوع پژوهش بستگی دارد.
مثلا پژوهشهای پایه و بنیادی در خصوص فرایندهای کلی انسانی، شامل پژوهشهای کیفی که به دنبال تعریف و کشف پدیده ها هستند، ارزش زیادی برای روایی بیرونی قائل اند.
چرا که این گونه پژوهشها به دنبال تعميم پذیری همگانی یافته های پژوهش هستند. مطالعات کاربردی نیز ممکن است به دنبال تعمیم یافته های خود باشند، هرچند به ندرت به آن حساس اند؛ مثلا ممکن است به دنبال تعمیم یافته ها به گروه خاصی از افراد باشند.
در پژوهش ارزشیابی و عمل گرا روایی بیرونی از اهمیت کمتری برخوردار است، چرا که این نوع مطالعات معمولا به دنبال فهمیدن با حل کردن یک مشکل خاص در یک موقعیت یا شرایط مشخص بوده و اگر به دنبال تعمیم پذیری باشد، آن را برای تعمیم دادن به آینده بسیار نزدیک می خواهد.
جامعه آماج
اولین گام در نمونه برداری مشخص کردن جامعه آماج است؛ برای نمونه جامعه آماج را می توان بر اساس جنس، طبقه اجتماعی، نوع مشکل با شدت بیماری تعیین نمود حتی می توان آن را به صورت محدود و مشخص تری مثلا زنان متأهل بين ۳۸-۴۸ سال، که در محدوده شهری گرگان زندگی می کنند و سابقه استفاده از داروهای روان پزشکی نیز ندارند، یا به صورت گسترده تری مثلا تمامی زنان ایرانی بالاتر از ۱۸ سال تعریف کرد.
جامعه همگن و ناهمگن
به جامعه های آماجی که به صورت مشخص و محدود تعریف می شوند جامعه همگن و به جامعه هایی که به صورت گسترده و کلی تعریف میشوند جامعه ناهمگن گویند.
و پژوهشگران به هنگام تصمیم گیری در خصوص وضعیت جامعه آماج بایستی تمامی جوانب و پیامدهای آن را در نظر بگیرند.
یکی از برتریهای نمونه همگن این است که میزان تغییر پذیریهای نامربوط در گروه نمونه را کاهش می دهد که این خود به محقق در کشف تأثیراتی که به دنبال آن است، توان بیشتری بخشیده، برآورد مقدار تأثیرات مورد نظر نیز از دقت و درستی بیشتری برخوردار خواهد بود.
در خصوص تحلیل واریانس، همگنی باعث کاهش میزان واریانس خطا" در واریانس كل می شود؛ برای مثال اگر شما تأثیر رویدادهای زندگی در افسردگی را مطالعه می کنید، هر چه نمونه ناهمگن تر باشد یافتن هر نوع رابطه ای بسیار سخت تر خواهد بود؛ چرا که عوامل و متغیرهای بسیار زیاد دیگری غیر از رویدادهای زندگی در ایجاد افسردگی مؤثر هستند.
از طرف دیگر افزایش دقت و درستی ناشی از تعریف محدود جامعه آماج معایبی در بر دارد که به قرار زیر است: قابلیت تعمیم یافته ها به مجموعه مرجع با جامعه کل را کاهش می دهد مثلا اگر محقق تنها زنان ۳۰ ساله را بررسی کند یافته هایش را نمی توان به زنان گروههای سنی دیگر تعمیم داد.
مشکلات عملی زیادی به وجود خواهد آمد که مهم ترین آن مشکل معیار ورودی است.
یعنی شرکت کنندگان با آزمودنیها برای ورود به گروه نمونه باید معیارهای خاصی داشته باشند که در این صورت بافتن آزمودنی بسیار مشکل خواهد بود.
چرا که بسیاری از افراد در مرحله غربال» از گروه نمونه حذف می شوند و در آن صورت، محقق بایستی افراد بسیار زیادی را در دسترس داشته باشد.
مینتز" (۱۹۸۱) از این مسئله به عنوان قانون وسكو و نام می برد. به محض اینکه به طور کامل یک جامعه را مشخص نمودید، آن جامعه ناپدید خواهد شدار
داشتن نمونه همگن مانع آزمودن تفاوتهای فردی شرکت کنندگان می شود!
مثلا اگر در نمونه شما تغییر پذیریهای کوچکی در متغير من وجود داشته باشد ( آزمودنیها به لحاظ سنی کمی با یکدیگر متفاوت باشند، نمی توانید سن را به عنوان متغير تفاوت فردی در نظر بگیرید (شاپیرو، ۱۹۸۹). روشهای نمونه گیری برای استنباط ویژگیهای جامعه آماج بر اساس ویژگیهای گروه نمونه ای که از آن جامعه گرفته شده است، گروه نمونه بایستی بدون جهت و سو گیری انتخاب شود.
بدین معنا که هر یک از افراد موجود در جامعه آماج بایستی برای انتخاب در گروه نمونه از شانس مساوی برخوردار باشند.
برای تشکیل یک گروه نمونه معرف، از فنون خاصی می توان استفاده کرد (کوچران، ۱۹۷۷؛ سادمن، ۱۹۷۶):
نمونه برداری تصادفی با احتمالی، نمونه برداری طبقه ای، نمونه برداری نظام دار، نمونه برداری خوشه ای، نمونه برداری سهمیه ای و نمونه برداری چند مرحله ای و برای مثال، در نمونه برداری تصادفی با احتمالی، هر یک از افراد جامعه آماج از شانس مساوی برای انتخاب برخوردارند (مثلا یک نفر از هر ده نفر)، در حالی که در نمونه برداری طبقه ای، جامعه آماج ابتدا و قبل از انتخاب به چندین گروه با طبقه ناهمپوش تقسیم می شود.
مثلا بر اساس طبقه اجتماعی با متغیرهای تشخیصی. بدین گونه که ابتدا کل افراد جامعه به گروههای مختلف تقسیم شده، آنگاه از هر طبقه یک نمونه تصادفی ساده انتخاب می شود.
البته قابل ذکر است که روان شناسان و به ویژه روان شناسان بالینی اهمیت زیادی به روش نمونه گیری نمی دهند، بلکه بیشتر به دنبال نمونه برداری راحت و آماده هستند (معمولا هر کسی را که با معیارهای مطالعه شان مطابقت داشته و در دسترس نیز باشد. انتخاب می کنند و چنانچه حجم نمونه به اندازه کافی بزرگ باشد، امکان تعمیم نتایج مطالعه شان نیز وجود خواهد داشت.
با وجود این، تصور غلطی است اگر بپنداریم نمونه ای که برای کشف معناداری آماری به اندازه کافی بزرگ است، مطمئنا برای تعمیم پذیری یافته ها کافی خواهد بود.
مهم نیست که حجم نمونه تا چه اندازه بزرگ است، بلکه پژوهشگر تنها زمانی می تواند به طور مطمئن بافته هایش را تعمیم دهد که گروه نمونه اش معرف جامعه آماج باشد.
در غیر این صورت، با وجود تعداد زیاد گروه نمونه باز هم تعمیم یافته ها با مشکل اساسی رو به رو خواهد بود. باید توجه داشت که حذف هر نوع سو گیری در نمونه برداری همیشه امکان پذیر نیست.
حتی در یک طرح نمونه برداری که به خوبی برنامه ریزی شده باشد نیز بعضا فاصله ای بین نمونه مورد نظر و نمونه اكتساب شده وجود دارد؛ برای مثال، در پژوهشهایی که از طریق پست کردن پرسشنامه ها به شرکت کنندگان انجام می گیرد، تقریبا یک سوم نمونه انتخابی به پرسشنامه پاسخی نمی دهند (دیلمن، ۱۹۷۸).
گروهی که به پرسشنامه ها پاسخی نمی دهند با گروه پاسخ دهنده به طور قابل توجهی تفاوت دارند؟ تفاوتهایی در میزان علاقه به شرکت در مطالعه، سطح انگیزش و سطح تحصیلات، به طور مشابه مطالعاتی که از طریق آگهی از افراد داوطلب استفاده می کند نیز ممکن است نمونه ای غیر معرفی را مورد آزمون قرار دهد.
گاهی اوقات این امکان وجود دارد تا ماهیت مو گیری در نمونه برداری را محاسبه کرده و سهم و تأثير تقریبی آن را به هنگام تحليل داده ها کنترل کنیم؟
مثلا اگر گروهی که پاسخ داده اند کلا از گروهی که پاسخ نداده اند مسن تر باشند، پژوهشگر می تواند به ارتباط بین سن و متغیرهای مورد مطالعه دقت نموده و احتمالا با استفاده از ضریب همبستگی سهمیه آثار آن را جدا نماید.
با این حال همان گونه که در بخش مربوط به طرح پیش آزمون - پس آزمون بر روی گروههای نامعادل بحث کردیم، «تعديل های آماری بعد از تجربه به دو دلیل فقط می تواند بخشی از آثار نمونه سوگیرانه با جهت دار را جبران نماید:
۱) بی اعتبار بودن سنجش و اندازه گیری و
۲) اینکه پژوهشگر هرگز نمی تواند به طور کامل برای تمامی متغیر هایی که سوگیری در آنها ممکن است رخ داده باشد، عمل جبرانی انجام دهد انجام تحلیل های تعدیلی بعد از تجربه» اغلب بسیار ارزشمند است، اما با پستی با دقت و احتیاط زیاد انجام گیرد یکی دیگر از اشکالات نمونه برداری با روی آورد دسترسی آسان به آزمودنیها استفاده از نمونه آماج) این است که گاهی اوقات گروههای خاصی ممکن است در نمونه ما معرف یا نماینده ای نداشته باشند؛ برای نمونه، گراهام' (۱۹۹۲) تمامی آزمودنیهایی را که در مطالعات منتشر شده در نشریات مهم انجمن روان شناسی امریکاهه شرکت داشتند بررسی کرد و به این نتیجه دست یافت که بیشتر آزمودنیها سفید و از طبقه اجتماعی متوسط هستند و بنابر این گروههای قومی و سیاه پوستان در پژوهشهای روان شناختی نادیده گرفته شده اند.
هنگامی که ترکیب و اندازه گروه آماج معلوم است، در ابتدا می توان از روش معروف به شبکه سازی» (پترون، ۱۹۹۰؛ روسی و فریمن، ۱۹۹۳) استفاده نمود. در این روش پژوهشگر از هر آزمودنی می خواهد تا یک یا چند نفر دیگر را که فکر می کند همانند خود او معیارهای شرکت در مطالعه را دارند معرفی نماید.
نمونه برداری تا زمانی که مشخص شود آزمودنیهای بعدی، دیگر اطلاعات بیشتری فراهم می آورند، ادامه می یابد؛ برای مثال، پیسترنگ (۱۹۹۰) از این روش برای مطالعه وضعیت بهداشت روانی جامعه چنیهای مقیم لندن استفاده کرد و همچنین خاور پور و صاحبی (۱۹۹۸) نیز از همین روش برای بررسی وضعیت بهداشتی جسمانی - روانی) و سبک زندگی ایرانیان در سیدنی استرالیا) از طریق مصاحبه تلفنی استفاده نمودند.
بدین صورت که چون تعداد ایرانیان مقیم در این شهر و محلی که بتوانند به آنان دسترسی داشته باشند نامشخص بود. از این رو با انتخاب ۵ آزمونگر و به دست آوردن ۱۰ شماره تلفن، هر پرسشگر مسئول آزمونگری ۲ نفر شد.
روش کار بر این منوال بود که در انتهای پرسشنامه وقتی که تمامی سوالات به پایان می رسید، از آزمودنی خواسته می شد تا در صورت تمایل اگر دوست، فامیل با آشنایی را می شناسد که:
۱) در حوزه شهری سیدنی زندگی می کند؛
۲) در ایران به دنیا آمده و حداقل یکی از والدینش ایرانی اند؛ و
۳) بیش از ۱۸ سال سن دارد معرفی نماید.
بدین طریق پژوهشگران توانستند به ۴۸۵ آزمودنی دست یابند.
با وجود این، یکی از مشکلات بالقوه روش شبکه سازی این است که پاسخ دهندگان با آزمودنیهای اولیه ممکن است پژوهشگر را به سمت افرادی متمایل کنند که دیدگاههای مشترک زیادی با خود آنها دارند؛ از این رو پژوهشگر باید نسبت به احتمال جهت دار بودن نمونه به دست آمده کاملا آگاه باشد.
حجم نمونه از دیدگاه استنباط آماری اولین قاعده صریح این است که هرچه گروه نمونه بزرگ تر باشد، بهتر است؛ چرا که پژوهشگر با نمونه بزرگتر بهتر می تواند واریانسهای مربوط به اثر متغیرهای مورد نظر را از واریانسهای ناشی از خطای نمونه برداری و خطای اندازه گیری متمایز سازد. به بیان دیگر، با وجود نمونه بزرگ، پژوهشگر بهتر می تواند صدا را از پارازیت تشخیص دهد.
با وجود این، همچنان که کوهن (۱۹۹۵) اشاره می کند، گاهی یک گروه نمونه می تواند بسیار بزرگ باشد؛ به این معنی که بیش از میزان مورد نیاز برای انوان آماری باشد که در این صورت چیزی جز اتلاف انرژی و هزینه پژوهش نیست.
از این رو در شرایط خوب بهترین عمل آن است که به جای انجام مطالعه با گروه نمونه بزرگت، چندین مطالعه کوچک انجام گیرد. استفاده از حجم نمونه کوچک و قابل دسترس همچنین ممکن است به جنبه های عملی نیز مربوط باشد، مثل مشکلات دستیابی به آزمودنی، محدودیتهای زمانی، کمبودهای مالی با مهیا بودن شرایط مطالعه تحلیل توان آماری بهترین و اصولی ترین راه برآورد حجم نمونه مناسب روشی است موسوم به اتحليل توان آماری، (کوهن، ۱۹۸۸، ۱۹۹۵، ۱۹۹۲؛ کریمر و تایمن، ۱۹۸۷؛ سیتگر ، لاوی" ولاوی، ۱۹۸۶).
به طور خلاصه توان آماری هر پژوهش، میزان احتمالی است که پژوهش می تواند تأثیرات موجود (آنچه مطالعه در پی یافتن آن است) را مشخص نماید؛ مثل تفاوت واقعی در میزان تأثیرات دو روش درمانی متفاوت.
مطالعه ای با توان آماری کم، شانس بسیار کمی برای یافتن چنین تأثیراتی خواهد داشت. در حالی که مطالعه ای با توان آماری بالا بهتر می تواند تفاوت با تأثيرات موجود را کشف نماید. بسیاری از مطالعات قبلی در حوزه روانشناسی بالینی و مشاوره توان آماری مناسبی نداشته اند، از این رو ممکن است از وجود تأثیرات مهم به سادگی چشم پوشی کرده باشند.
برای فهم بهتر چگونگی برآورد حجم نمونه و توان آماری و نقش آن در پژوهش بهتر است ابتدا به مسئله تصمیم گیری در استنباط آماری بپردازیم تا بدین طريق موضوع توان آزمون آماری روشن تر شود در استنباط آماری، پژوهشگر همواره در نقش یک تصمیم گیرنده ظاهر می شود که کار او «رد فرضیه صفر یا عدم رد فرضیه صفر است.
پژوهشگر برای کسب اطمینان از تصمیم خود بایستی تمامی جامعه آماری را مطالعه کند؛ اما به دلیل حجم بسیار زیاد جامعه مورد مطالعه در علوم رفتاری، بررسی تمامی جامعه امکان پذیر نیست. از این رو، پژوهشگر همواره برای آنکه در خصوص وضعیت واقعی جامعه تصمیم بگیرد، از طریق نمونه برداری از میان افراد جامعه مورد نظر یک گروه نمونه انتخاب می کند و بر اساس یافته های به دست آمده از گروه نمونه، فرضیه صفر را رد یا قبول می کند.
به همین دلیل پژوهشگر همیشه در تصمیمات خود با نوعی عدم اطمینان روبه روست فرض کنید پژوهشگری به دنبال بررسی میزان اضطراب امتحان در دختران و پسران دانشجوست و علاقه مند است بداند که آیا میانگین اضطراب در دختران با میانگین اضطراب در پسران تفاوت دارد یا خیر.
نظر پژوهشگر با توجه به تجارب شخصی و مطالعات قبلی این است که پسران به طور متوسط میزان اضطراب بیشتری را در امتحان تجربه می کنند.
برای کسب اطمینان، او نمونه ای ۱۰۰ نفره (۱۰۰=n) از میان دانشجویان دانشگاه فردوسی انتخاب می کند (۵۰ پسر و ۵۰ دختر) و با اجرای یک آزمون اضطراب امتحان، نمره اضطراب آنان را به دست می آورد. میانگین نمره پسران ۲۶ (با انحراف معیار 3) و میانگین نمره دختران ۲۱ (با انحراف معیار ۲) محاسبه شده است.
حالا چون میانگین دو گروه با هم د نمره تفاوت دارد، آیا پژوهشگر می تواند نتیجه بگیرد که میزان اضطراب امتحان در پسران بیشتر از دختران است؟
برای پاسخگویی به این پرسش ابتدا باید به این نکته مهم توجه داشت که چون تمامی دانشجویان بررسی نشده اند، این احتمال وجود دارد که میانگینهای به دست آمده (۲۱ و ۲۶) میانگینهای واقعی تمام دانشجویان نباشد.
بنابراین در این خصوص مقداری عدم اطمینان وجود دارد که خود باعث می شود تا پژوهشگر نتواند قاطعانه اظهار نظر کند. در اینجا سؤال دومی مطرح می شود که: «میزان احتمال مشاهده میانگین ۲۶ زمانی که میانگین واقعی جامعه ۲۱ است، چقدر است؟، که با توجه به تعیین سطح اطمینان (۰۵/ه یا 001=) اگر مقدار احتمال مشاهده میانگین نمونه ای برابر یا بزرگ تر از ۲۶ در جامعه ای با میانگین واقعی ۲۱ از ۵ درصد کمتر باشد، می توان نتیجه گرفت که میانگین جامعه برای دانشجویان پسر از ۲۱ بالاتر است.
چنانچه مقدار احتمال از ۵ درصد بیشتر باشد، نتیجه گرفته می شود که مدارک کافی برای تصمیم گیری اینکه میانگین جامعه دانشجویان پسر با دانشجویان دختر تفاوت دارد، موجود نیست. تصمیم گیری در استنباط آماری در نمونه قبلی، پژوهشگر به دنبال این بود که بداند میانگین اضطراب امتحان در پسران از میانگین اضطراب امتحان در دختران دانشجو بیشتر است یا خیر؟
پاسخ از دو حال خارج نیست: با میانگین اضطراب امتحان پسران مورد مطالعه برابر با میانگین اضطراب امتحان دختران است ( = ) یا از آن بیشتر است (H۲ < (). اما واقعیت آن است که پژوهشگر از وضعیت واقعی جامعه دانشجویی بی اطلاع است. بنابراین به وسیله مطالعه گروه نمونه وضعیت واقعی جامعه را استنباط می کند و در خصوص میانگین واقعی تصمیم می گیرد.
مسئله تصمیم گیری دو ویژگی دارد ، در جامعه واقعیتی وجود دارد و پژوهشگر به دنبال دانستن آن است (در این مثال وضعیت واقعی میانگین در دانشجویان، مورد علاقه پژوهشگر است)
پژوهشگر باید وضعیت واقعی جامعه را از طريق مطالعه داده های نمونه با مقداری خطا استنباط نماید (شیولسون، ۱۹۸۱) که موضوع خطای نوع اول و دوم مطرح می شود احتمال خطای نوع اول و نوع دوم. مسئله تصمیم گیری را می توان در قالب آزمون فرضیه بیان کرد. در نمونه ذکر شده با این وضعیت رو به رویم.
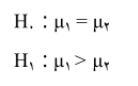
در جامعه واقعی فرضیه صفر یا درست است یا درست نیست؛ یعنی یا میانگین اضطراب امتحان در پسران مساوی با دختران است یا با هم مساوی نیست. محقق بر اساس نمونه تصادفی تصمیم می گیرد که فرضیه صفر را یا رد کند یا رد نکند که این تصمیم گیری یا درست خواهد بود یا نه. جدول ۱-۹ وجوه مختلف تصمیم گیری را نشان می دهد. تصمیم پژوهشگر درست خواهد بود اگر:
یک فرضیه صفر درست را رد نکند؛
یک فرضیه صفر نادرست را رد کند.
جدول زیر همچنین دو نوع خطای احتمالی در تصمیم گیری را نشان می دهد:
خطای نوع اول: رد یک فرضیه درست
خطای نوع دوم: عدم رد یک فرضیه نادرست.
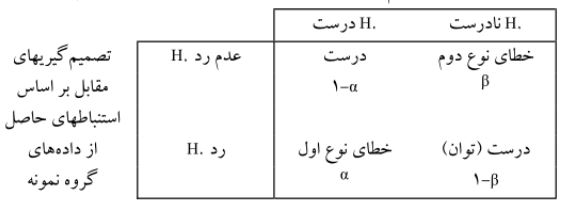
همان طور که مشاهده می شود ستون اول جدول مذکور به درست بودن فرضیه صفر می پردازد؛ به ویژه به خطای ناشی از رد فرضیه صفر وقتی که فرضیه صفر درست است.
برای پیشگیری از این خطا میزان احتمال (a) رد فرضیه صفر زمانی که فرضیه صفر درست است را به صورت کاملا محتاطانه ۵ درصد یا ۱ درصد انتخاب می کنیم.
بنابراین احتمال رد نکردن فرضیه صفر وقتی که فرضیه صفر درست است، برابر است با -1.
چنانچه آنها را مساوی با ۵ درصد بگیریم (۵٪= ) احتمال تصمیم گیری درست هنگامی که فرضیه صفر درست است برابر خواهد بود باز ۱- ۰/۰۵ = ./۹۵ همچنان که از جدول بر می آید، فرضبه صفر می تواند درست باشد.
بدین ترتیب مسئله تصمیم گیری شکل دیگری به خود می گیرد. برای فهم بهتر مسئله، فرایند پژوهش را مجددا مرور می کنیم، هر پژوهش بدین دلیل انجام می گیرد که پژوهشگر دلایل قانع کننده ای در مورد نادرست بودن فرضیه صفر در اختیار دارد. چنانچه چنین دلایلی در دست نباشد، اصل بررسی و جستجو بی معنی خواهد بود. در مثال ذکر شده، پژوهشگر به بررسی میزان اضطراب امتحان در دختران و پسران دانشجو پرداخته است، زیرا پژوهشهای قبلی با تجارب شخصی پژوهشگر احتمالا تفاوت بین این دو گروه را گوشزد نموده اند.
در پژوهشهای تجربی، پژوهشگر معمولا فرضیه صفر را بیان می کند و آنگاه تلاش می کند تا شواهد کافی جهت رد آن فراهم سازد. موفقیت پژوهشگر در جمع آوری شواهد کافی جهت رد فرضیه صفر به طور غیر مستقیم تأیید کننده فرضیه مقابل (فرضیه پژوهش) خواهد بود.
از این رو، شاید بتوان گفت که پژوهش از آغاز به دلیل فرضیه مقابل طراحی می شود. با توجه به مطالب مطرح شده، مشخص می شود که ستون دوم این جدول با پژوهش ارتباط بسیار زیادی دارد، هنگامی که فرضیه صفر درست نباشد، تصمیم پژوهشگر مبنی بر پذیرش آن خطا خواهد بود که به آن خطای نوع دوم گویند و احتمال آن را با 8 نشان می دهند. 6 = (خطای نوع دوم) P = (عدم رد .H نادرست) =P هنگامی که فرضیه صفر نادرست است و پژوهشگر هم تصمیم به رد آن می گیرد یعنی آنچه در پژوهش به دنبال آن است)، تصمیم او درست خواهد بود.
به احتمال اخذ تصمیم درست یعنی رد فرضیه صفر نادرست توان آزمون آماری» گفته می شود. همان طور که گفته شد، توان آزمون آماری بیانگر میزان احتمالی است که اگر واقعا تفاوتی وجود داشته باشد، پژوهش آن تفاوت را نشان دهد.